Retrospective
Reaching our goal was not easy, we failed many times but finally made it and proved that our original idea was not only working but also was very convenient to work with while being amazingly efficient.
What we learned on the road
The first thing we want to emphasize is that load testing is more than useful.
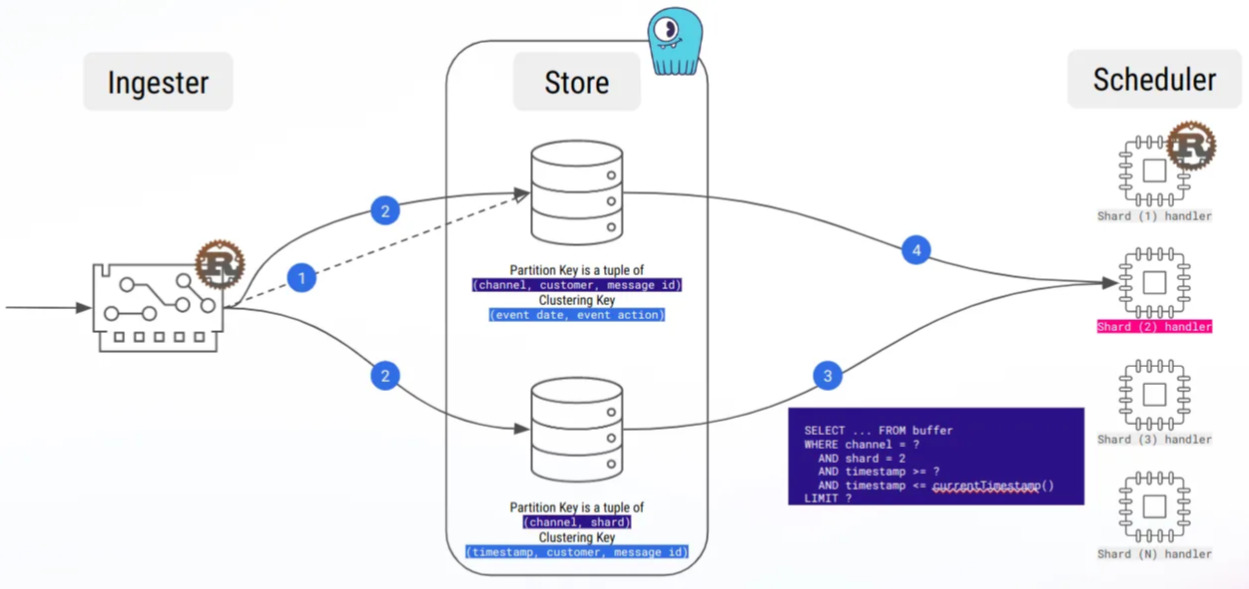
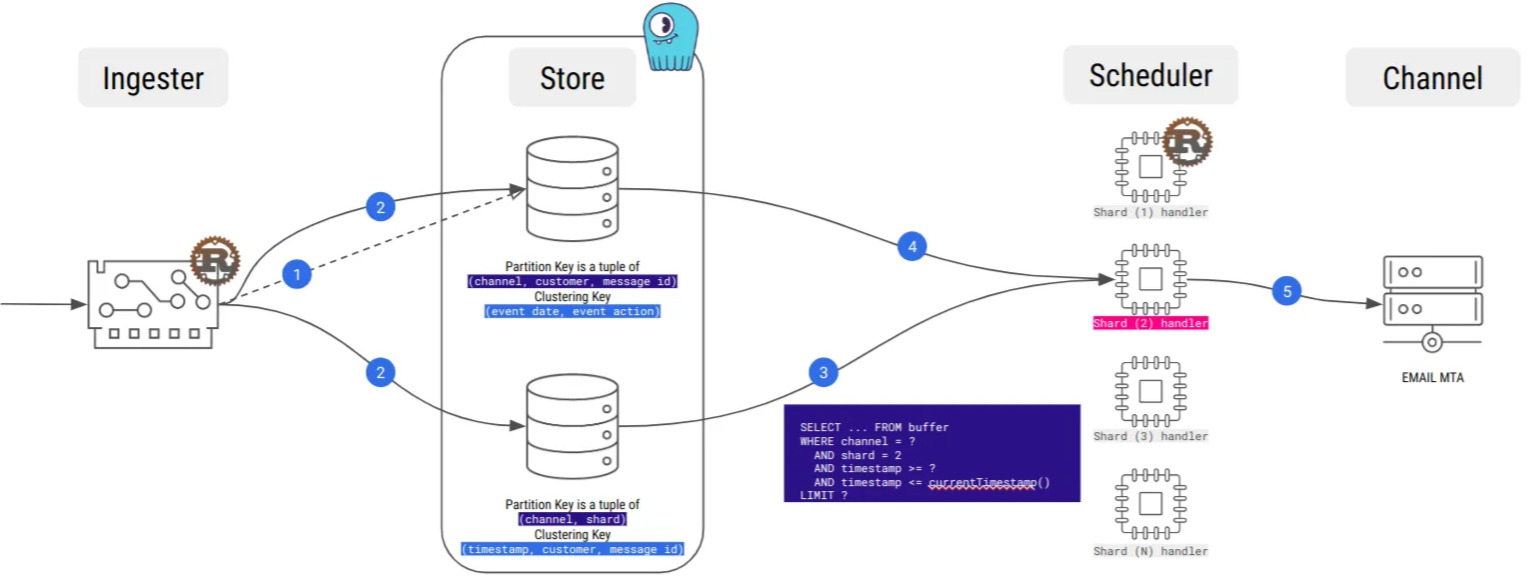
Quickly enough during the development, we set up load tests, sending dozens of thousands message per second. Our goal was to test our data schema design at scale and idempotence guarantee.
It allowed us to spot multiple issues, sometimes non trivial, like when the execution delay between the statements of our insertion batch was greater than our fetch time-window. Yeah, a nightmare to debug…
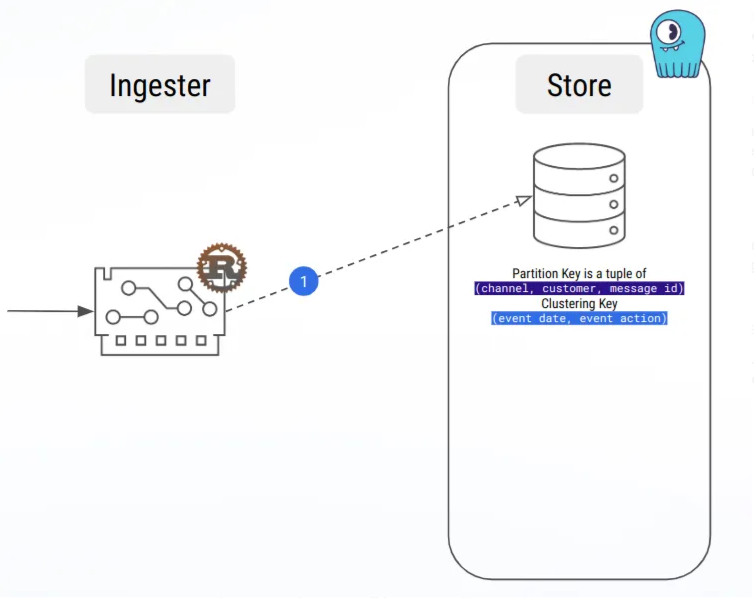
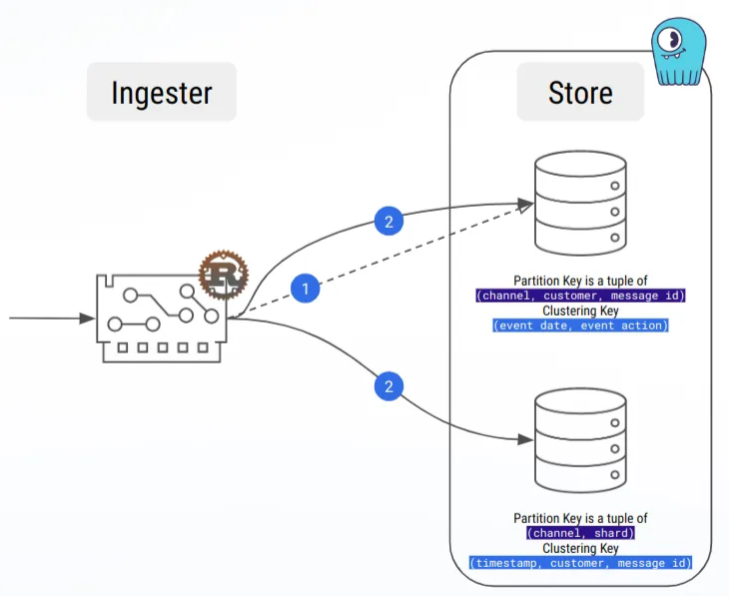
By the way, our first workload was a naive insert-and-delete, and load testing made large partitions appear very fast!
Hopefully, we also learned about compaction strategies, and especially the Time-Window Compaction Strategy, which we are using now, and which allowed us to get rid of the large partitions issue.
Message buffering as time-series processing allowed us to avoid large partitions!
We contributed to the ScyllaDB Rust driver
To make this project possible, we contributed to the ScyllaDB ecosystem, especially to the Rust driver, with a few issues and pull requests.
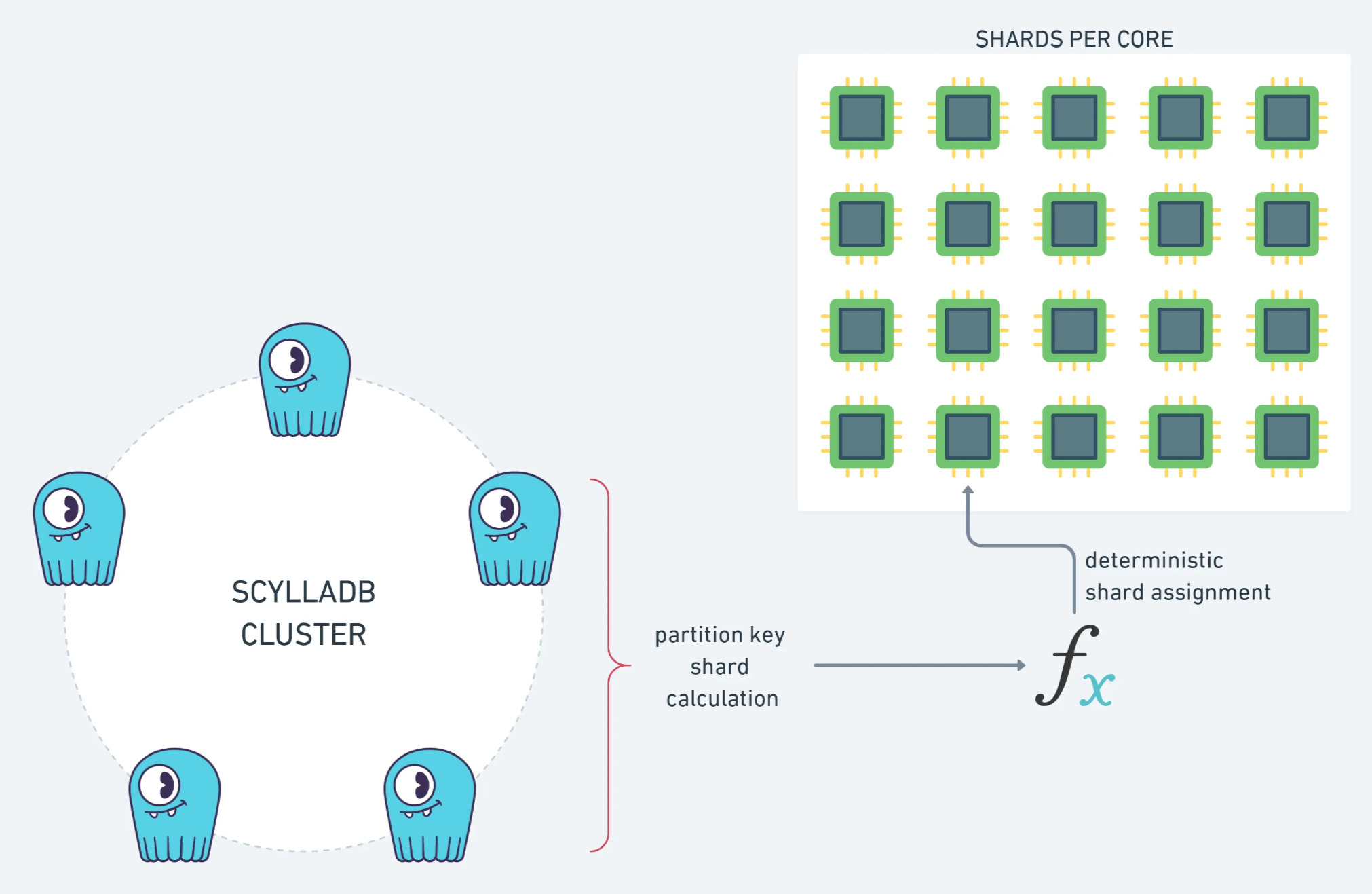
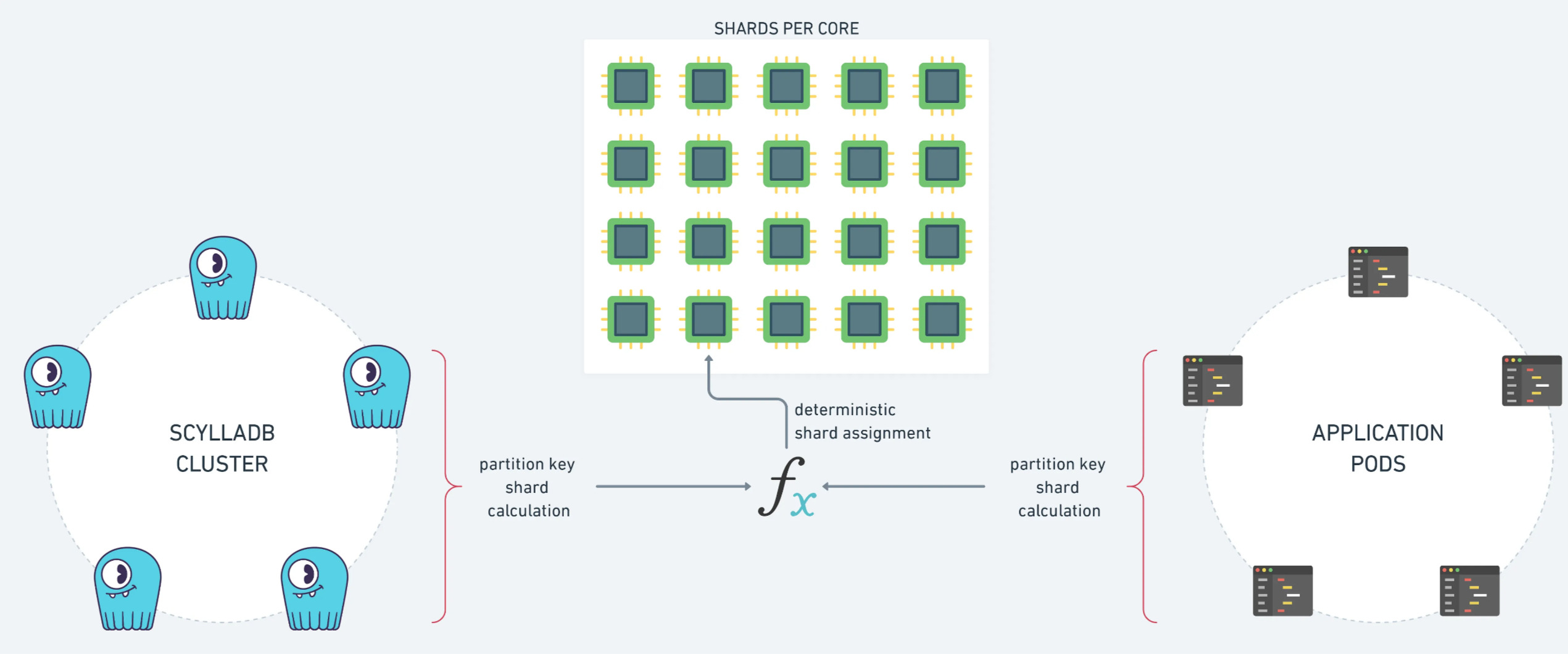
For example, we added the code to compute the replica nodes of a primary key, as we needed it to compute the shard of a message:
We hope it will help you if you want to use this cool sharding pattern in your future shard-aware application!
We also discovered some ScyllaDB bugs, so of course we worked with ScyllaDB support to have them fixed (thanks for your reactivity).
What we wish we could do
As in all systems, everything is not perfect, and we have some points we wish we could do better.
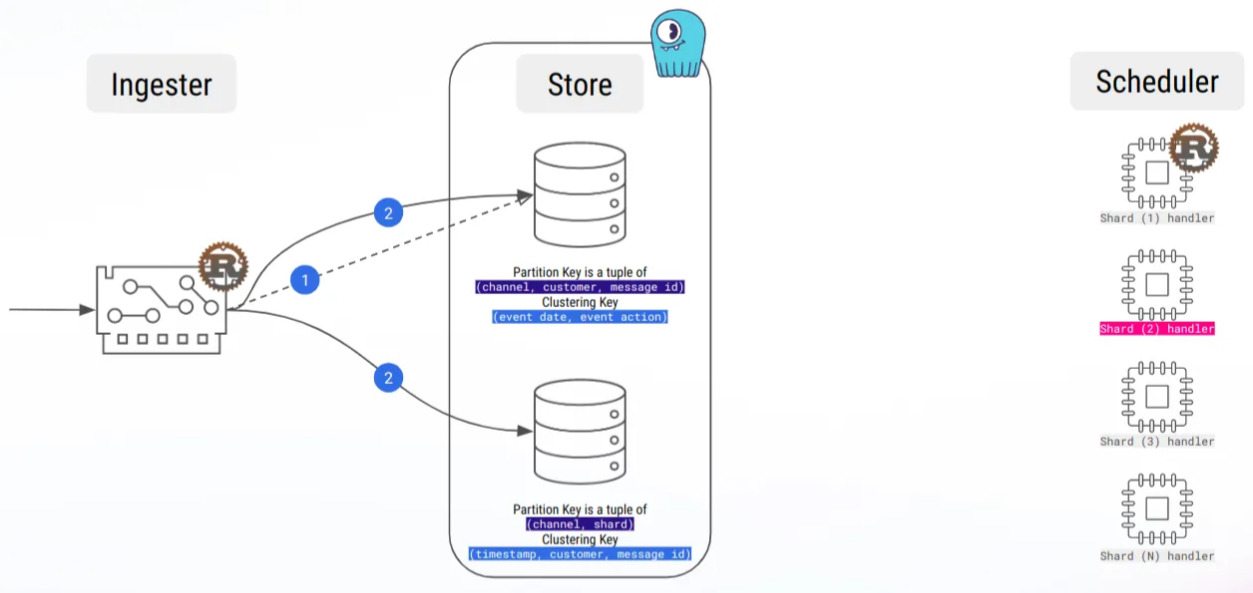
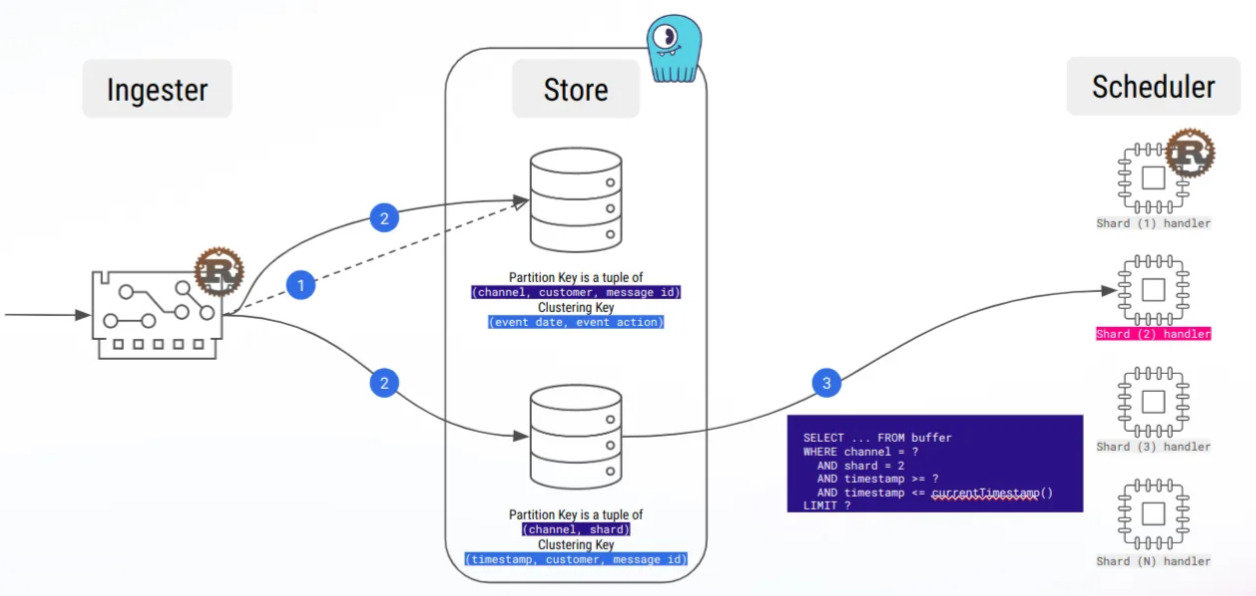
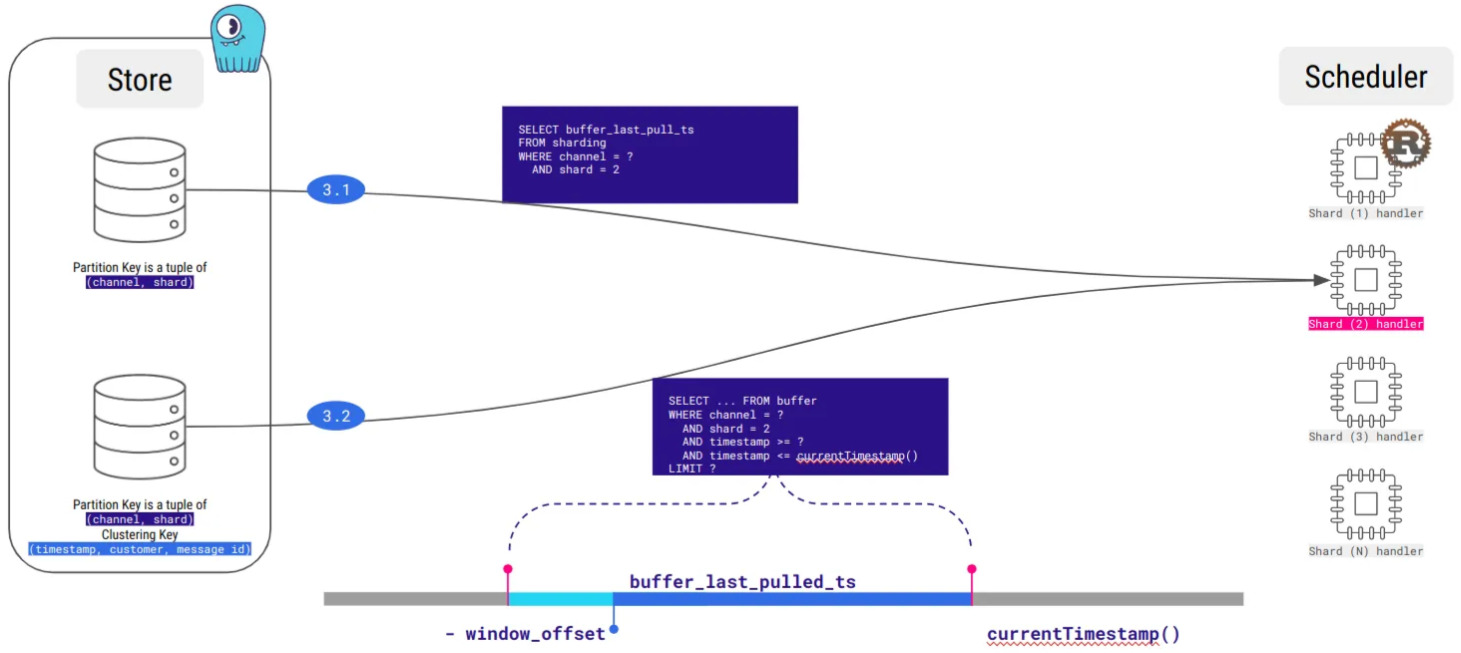
Obviously, ScyllaDB is not a message queuing platform, and we miss Kafka long-polling. Currently, our architecture does regular fetching of each shard buffer, so that’s a lot of useless bandwidth consumed, but we are working on optimizing this.
Also, we encountered some memory issues, where we did suspect the ScyllaDB Rust driver. We didn’t take so much time to investigate, but it made us dig into the driver code, where we spotted a lot of memory allocations.
As a side project, we started to think about some optimizations; actually, we did more than think, because we wrote a whole prototype of an (almost) allocation-free ScyllaDB Rust driver.
We will maybe make it the subject of a future blog post, with the Rust driver outperforming back the Go driver!
Going further with ScyllaDB features
So we bet on ScyllaDB, and that’s a good thing, because it has a lot of other features that we want to benefit from.
For example Change Data Capture: using the CDC Kafka source connector, we could stream our message events to the rest of the infrastructure, without touching our application code. Observability made easy.
We are looking forward to the ScyllaDB path towards strongly consistent tables with Raft as an alternative to LWT.
Currently, we are using LWT in a few places, especially for dynamic shard workload attribution, so we can’t wait to test this feature!
Written by Alexys Jacob, CTO.