
by Vincent Fricotteaux, Data Ops Engineer
Disclaimer: the vision shared in this article corresponds to a specific context and need, which are those of Numberly for whom Data is a core value. It may not apply well to your context.
DBA: a profession that is not disappearing, but evolving.
by Vincent Fricotteaux, Data Ops Engineer
Disclaimer: the vision shared in this article corresponds to a specific context and need, which are those of Numberly for whom Data is a core value. It may not apply well to your context.
It was inevitable. The DBA profession as we have known it, guaranteeing the maintenance and optimisation of our data infrastructures, is now on the decline. Sad news, isn’t it? But is it in danger? Certainly not.
On the contrary, it is a profession that is becoming more and more meaningful with the advent of the various engine solutions that have multiplied over the last ten years. From the good old relational model, there was the emergence of NoSQL, a veritable hodgepodge of ideas meeting specific needs, and today we are talking about New SQL, a new kind of engine to rule them all. The environment has also changed, data has become a highly coveted raw material, carrying a need for legislation (just like GDPR) and quality management.
Faced with such a landscape, it is difficult to do without the conductor of the orchestra that is our dear DBA. However, we need to take a fresh look at the function and the objectives it must achieve.
Indeed, the stakes have changed. Data has become a central value in technical professions, and the way in which it is served is changing with time and new technologies. Should we serve data on ScyllaDB as we would on PostgreSQL? Certainly not. Do you have to be a Neo4j and Elasticsearch expert when you are a DBA? Very few can really boast that. So what has become of the DBA if he is no longer the expert on his preferred technology?
This is the answer we have decided to provide at Numberly. The position of DBA, guarantor of the integrity and secure access to highly available data, has evolved into a more global function of what we call Data Ops: the meeting of agile development methodologies and data infrastructure administration needs, in line with the “Ops” movements (Dev Ops, Net Ops, etc. described here) that have emerged in recent years.
There is indeed a convergence between the need to automate the maintenance of database engines and the need to rely on automation and industrialisation tools such as those used by Dev Ops teams.
With the arrival of tools such as Gitlab, Ansible and Terraform, and agile deployment methodologies such as CI/CD, this movement makes total sense and we have the necessary means to make it happen!
The mindset then evolved. Database infrastructure management is no longer done through proprietary tools, but through code. Python has replaced all the specific bricks to bring a converged vision of the administration methodology.
Looking for backup scripts? These are cronjobs on Kubernertes. You want to install a new instance of your engine? Ansible is the place to go.
As you can see, “infrastructure as code” has become part of the DBA’s daily life, echoing the needs of the infrastructure and Dev Ops teams, thus providing a fluid way of working.
In order to better understand how this vision offers new possibilities, we propose to illustrate it with a very concrete case.
At Numberly we manage several database models. These models exist on several databases at the same time, and it is our responsibility to ensure that these models are consistent with each other. To make matters even more complex, these models must be carried by engines with different visions.
We therefore had to imagine a solution to ensure convergence in our deployment methods without being locked into the specificities of this or that database engine.
In order to meet this need, a DBA vision (security, accessibility, etc.) and a Dev Ops vision (automated deployments, centralisation, versioning, etc.) are required. The job of Data Ops represents the union of these two roles.
We have devised a solution that draws on the strengths of Gitlab to centralise model development requests, thus securing direct access to modified objects, whilst taking advantage of Git for the traceability of modifications made and of CI/CD to automate the deployment of these models on the target databases. Thanks to Python and the infinite possibilities that this language includes, we can deliver these models on any database engine in a unified way.
All this together brings a declarative, centralised and common vision for all teams working on Data!
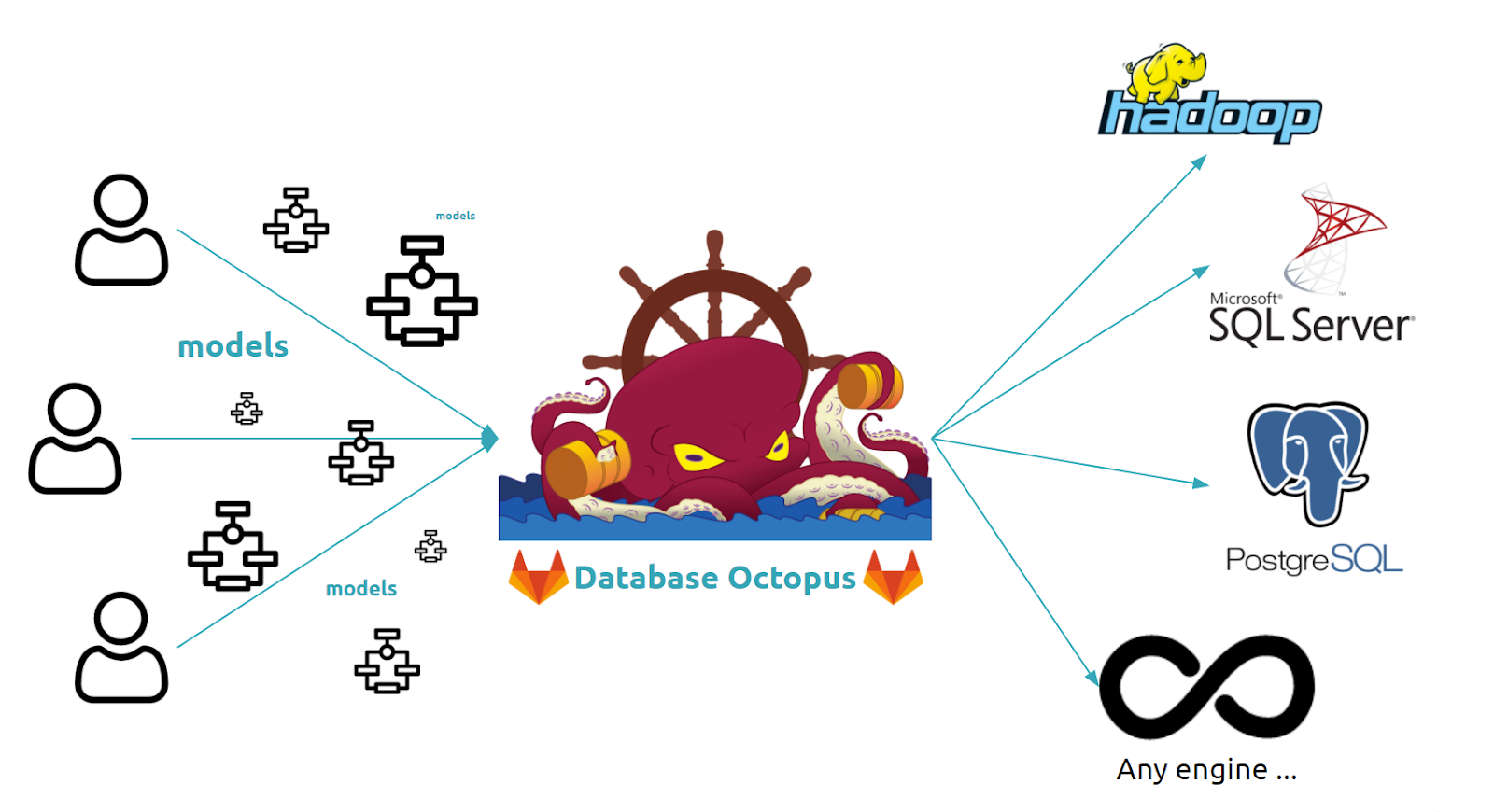
“Octopus database, our centralised model management solution
With these tools, the DBA function is more meaningful than ever. They provide answers to questions that are sometimes left unanswered, enable new working methodologies, and bring about a convergent way of working with other technical teams.
All of this raises the question: What is the process for moving towards a Data Ops function, and what are the tools?
What will really make you reconsider the DBA function will often be the volume. You don’t handle a few gigabytes on a relational engine, instead, a several petabytes spread over several distinct technologies, geo-distributed, redundant, sharded, etc. It is at this point that we must ask ourselves the question: how can we industrialise and automate all this data so that it becomes humanly manageable and observable? And the answer is often found in the code.
Here are some tools that will allow you to challenge your DBA environment:
This list is obviously not exhaustive, but it already gives you an idea of the tools that accompany the daily life of a data operator.