Afin de mieux comprendre en quoi cette vision offre de nouvelles possibilités, nous vous proposons de l’illustrer par un cas très concret.
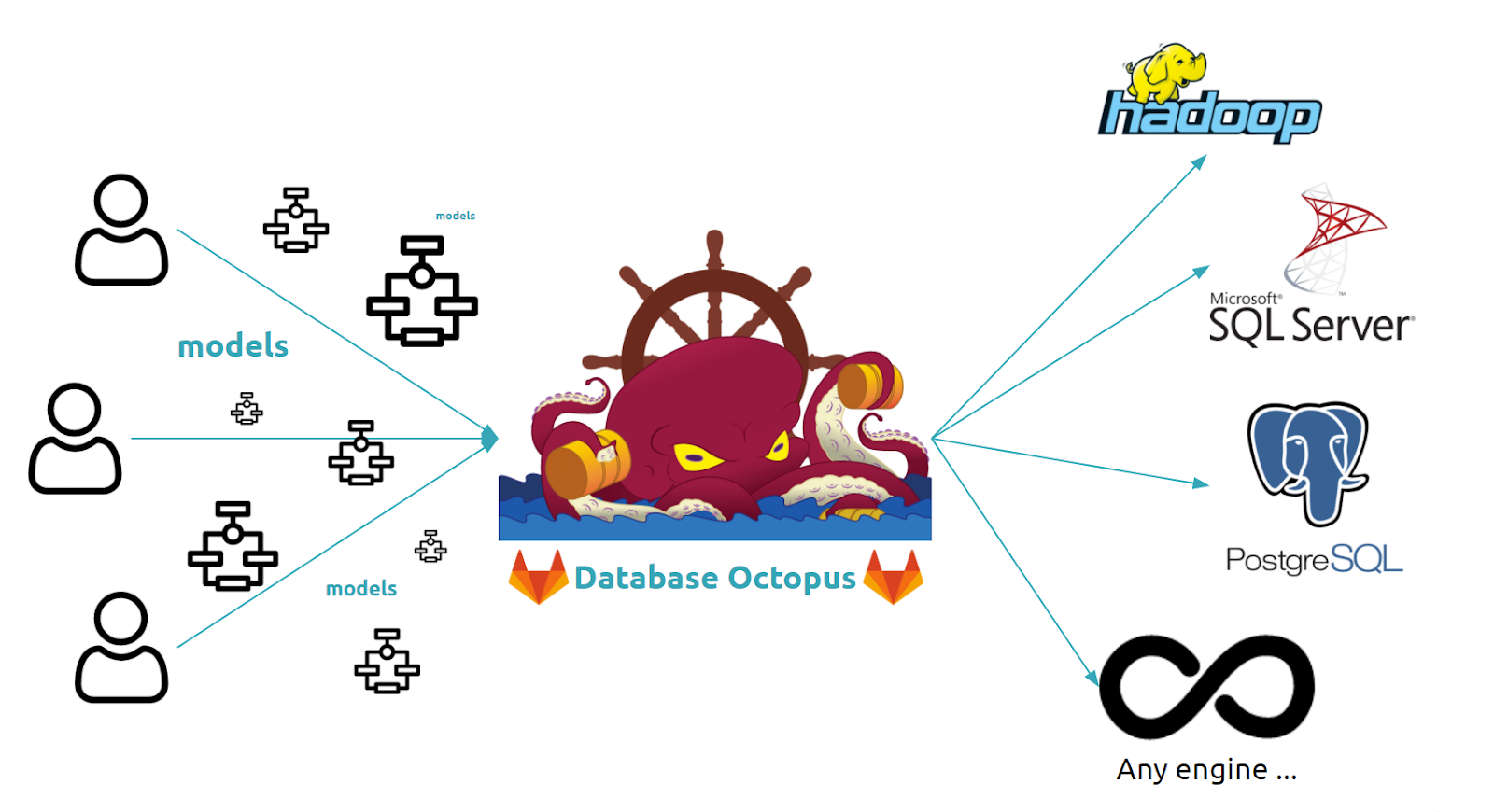
Chez Numberly nous gérons plusieurs modèles de bases de données. Ces modèles existent sur plusieurs bases au même moment, et il est de notre responsabilité de s’assurer que ces modèles soient cohérents entre eux. Pour encore complexifier le sujet, ces modèles doivent être portés par des moteurs aux paradigmes différents.
Il a alors fallu imaginer une solution pour assurer une convergence dans nos méthodes de déploiement sans s’enfermer dans les spécificités de tel ou tel moteur de base de données.
Afin de répondre à ce besoin, il faut donc une vision DBA (sécurité, accessibilité, etc.) et une vision Dev Ops (déploiements automatisés, centralisation, versioning, etc.). Le métier de Data Ops représente alors l’addition de ces deux sensibilités.
Nous avons imaginé une solution qui s’appuie sur les forces de Gitlab pour centraliser les demandes de développements de modèles, sécurisant ainsi les accès directs aux objets modifiés, tout en tirant l’avantage de Git pour la traçabilité des modifications apportées et de la CI/CD pour automatiser le déploiement de ces modèles sur les bases cibles. Grâce à Python et les infinies possibilités que ce langage comprend, on peut donc délivrer ces modèles sur n’importe quel moteur de base de données de manière unifiée.
Tout ceci mis ensemble apporte une vision déclarative, centralisée et commune pour toutes les équipes qui travaillent sur la Data !