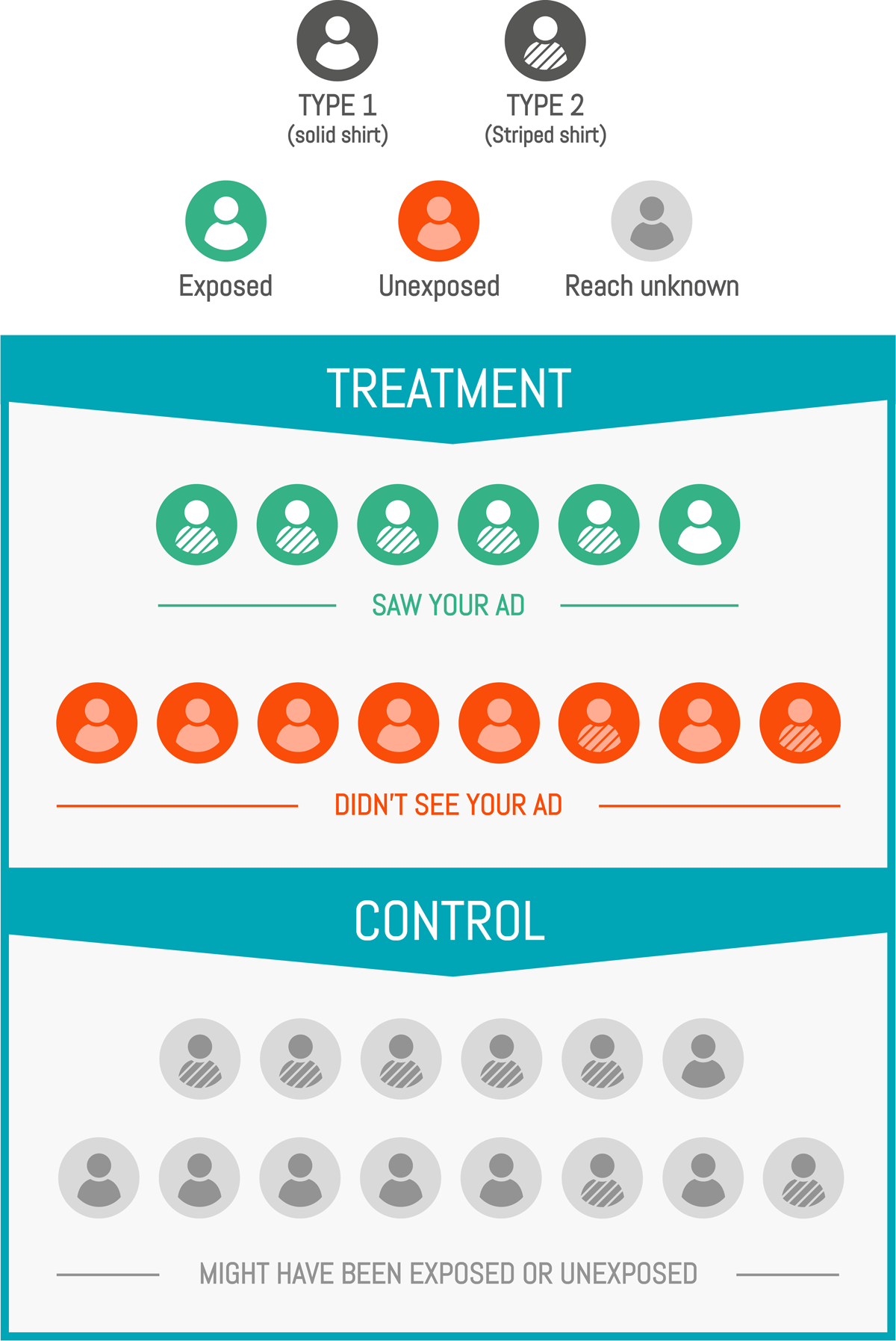
In pharmaceutical studies, biases can intervene while trying to measure the true effect of a given drug. The reader is probably familiar with the placebo effect for example: taking a drug, even ineffective, can have a significant psychological (and then physical) effect. Another less famous phenomenon is the possibility for the patient to refuse medication, or pretend to follow a treatment while actually not using the drugs. This behavior can be caused by some pathology or could be the patient’s own choice. If the placebo effect is not that relevant to our marketing study, the latter is crucial: indeed, just like people can refuse to take a pill even though they received the true treatment, people can avoid exposition to an ad even though they are in the targeted test group (for example, if the person is on holiday during the campaign and no impression is available).
We then distinguish two measured effects:
- Intent-to-treat (ITT): This represents how the prescription of the drug affects the health of a patient, without knowing if they will actually take it or not.
- Local Average Treatment Effect (LATE): This captures the actual effect of taking the drug on the health of a patient.
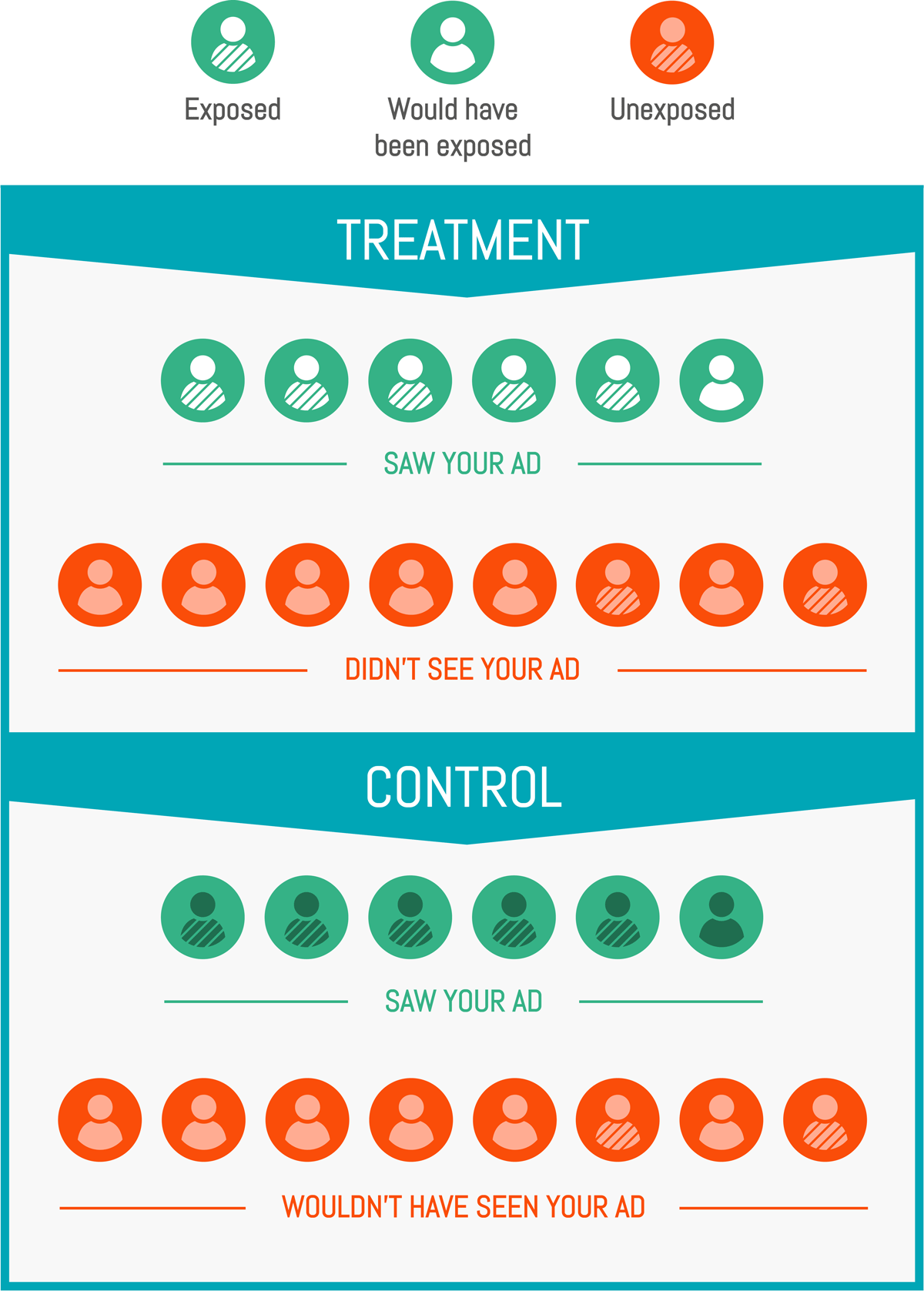
In our case, we can assimilate the ITT effect to our targeting: what is the incremental effect of targeting a population? The LATE is the exposure effect: what is the incremental effect on those who saw our ad?
The ITT is the most global and least detailed indicator: it combines the LATE effect and the probability of exposure in one.
It is easy to measure: you simply need to compare your test and control group. The LATE is more tricky: you cannot compare exposed to unexposed customers because, as we saw earlier, your exposable customers (those that are easy to reach, as opt-in for CRM programs or internet natives for media audiences) are inherently better than the rest.
For example, let’s take a mailing campaign that generates a 10% increase in sales.
You know that people who always open emails from your brand are your engaged customers. Let’s assume they generate 50% more sales in general than your regular customers.
Those customers will generate (1+10%)*(1+50%) = 65% more sales than the others. But you will only be able to measure that 65% (cumulative effect of ad + bias on engaged customers), and what you want to measure is the 10% increase in sales.
This is why we take into account the exposure rate, pollution (customers in the control group that were exposed unintentionally), technical limitations, and several parameters of the campaign (total and frequency of exposure, visibility, duration) to compute the actual effect estimated for the campaign, our Local Average Treatment Effect.