Rétrospective
Atteindre notre objectif n’a pas été facile, nous avons échoué à plusieurs reprises, mais nous avons finalement réussi et prouvé que notre idée originale ne fonctionnait pas seulement, mais qu’elle était aussi très pratique à utiliser tout en étant incroyablement efficace.
Ce que nous avons appris
La première chose que nous voulons souligner est que les tests de charge sont plus qu’utiles.
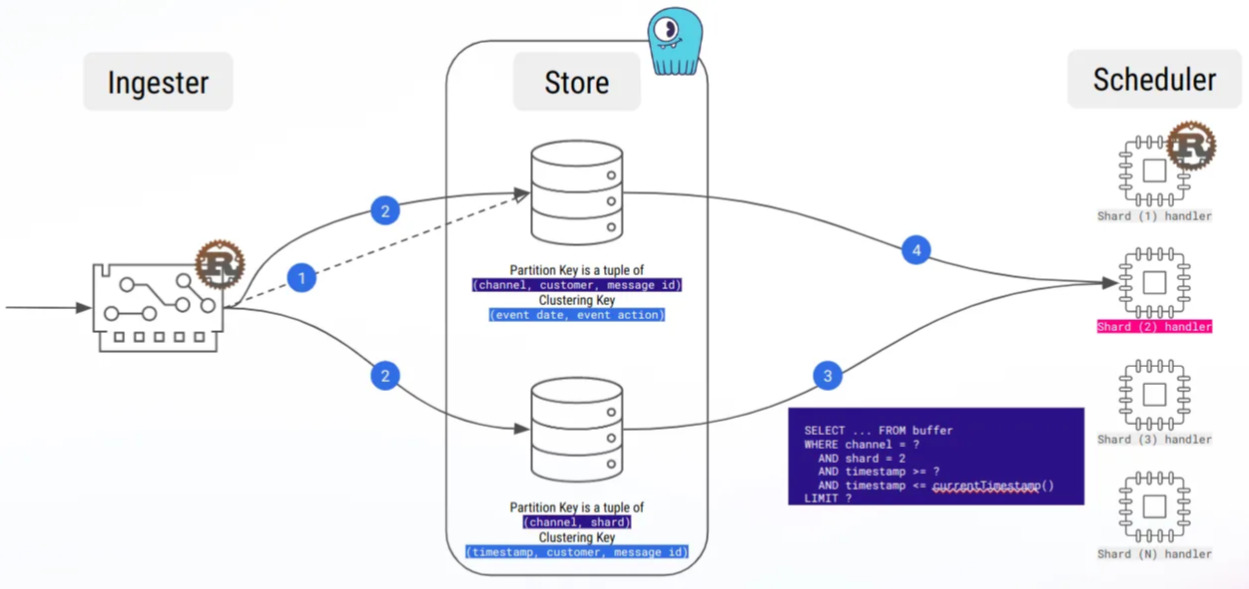
Assez rapidement au cours du développement, nous avons mis en place des tests de charge, envoyant des dizaines de milliers de messages par seconde. Notre objectif était de tester la conception de notre schéma de données à l’échelle et la garantie d’idempotence.
Cela nous a permis de repérer de nombreux problèmes, parfois non triviaux, comme lorsque le délai d’exécution entre les instructions de notre lot d’insertion était supérieur à notre fenêtre temporelle de récupération. Oui, un cauchemar à débugger…
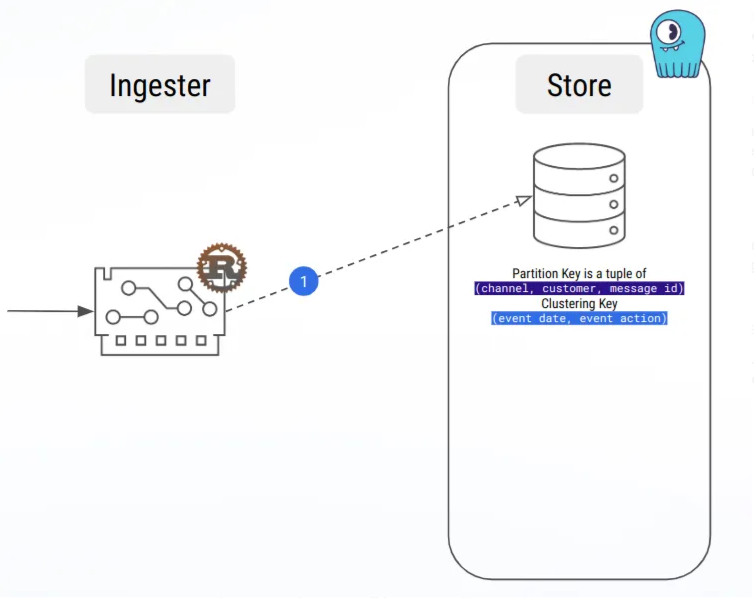
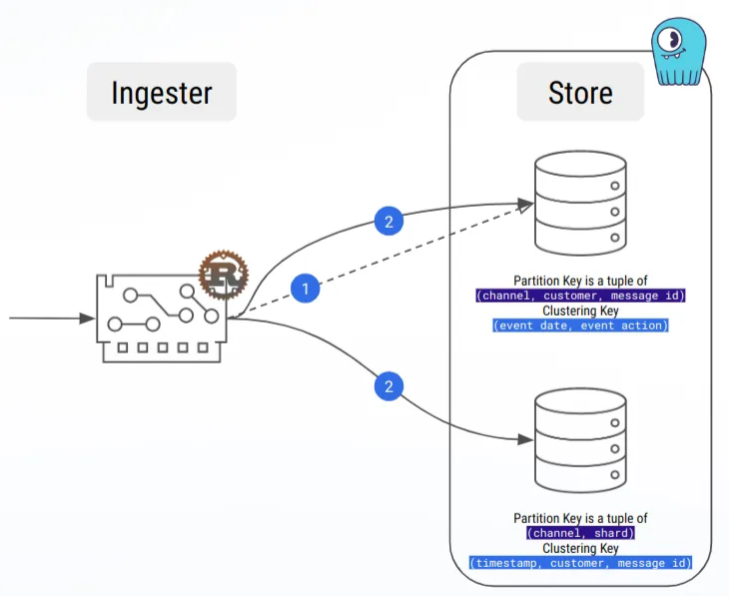
D’ailleurs, notre première charge de travail était une insertion et une suppression naïves, et les tests de charge ont montré que les grandes partitions étaient très rapides !
Heureusement, nous avons également appris à connaître les stratégies de compactage, et en particulier la stratégie de compactage par fenêtre temporelle, que nous utilisons actuellement et qui nous a permis de nous débarrasser du problème des grandes partitions.
- La mise en mémoire tampon des messages lors du traitement des séries temporelles nous a permis d’éviter les grandes partitions !
Nous avons contribué au pilote Rust de ScyllaDB
Pour rendre ce projet possible, nous avons contribué à l’écosystème ScyllaDB, en particulier au pilote Rust, avec quelques problèmes et pull requests.
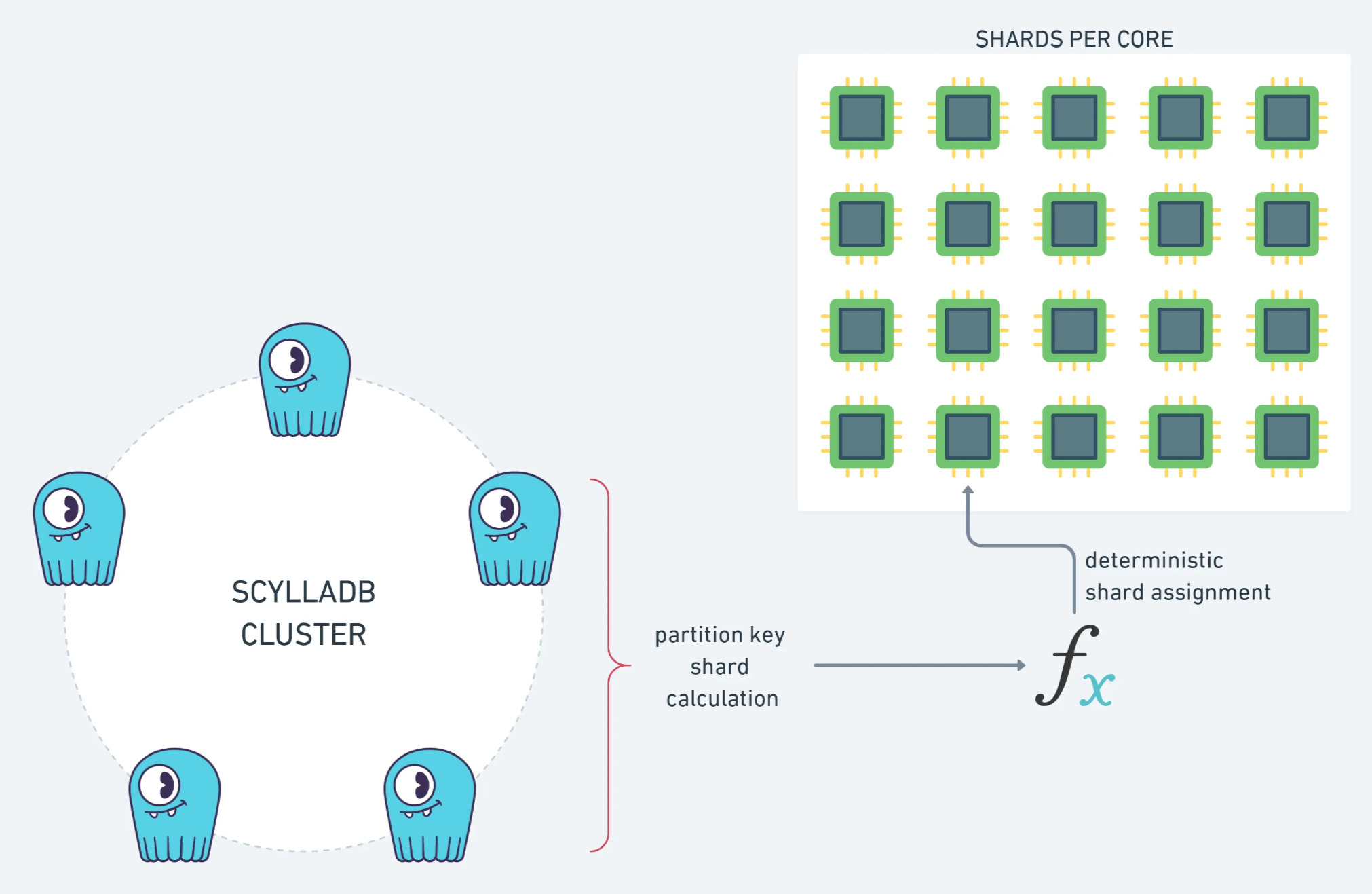
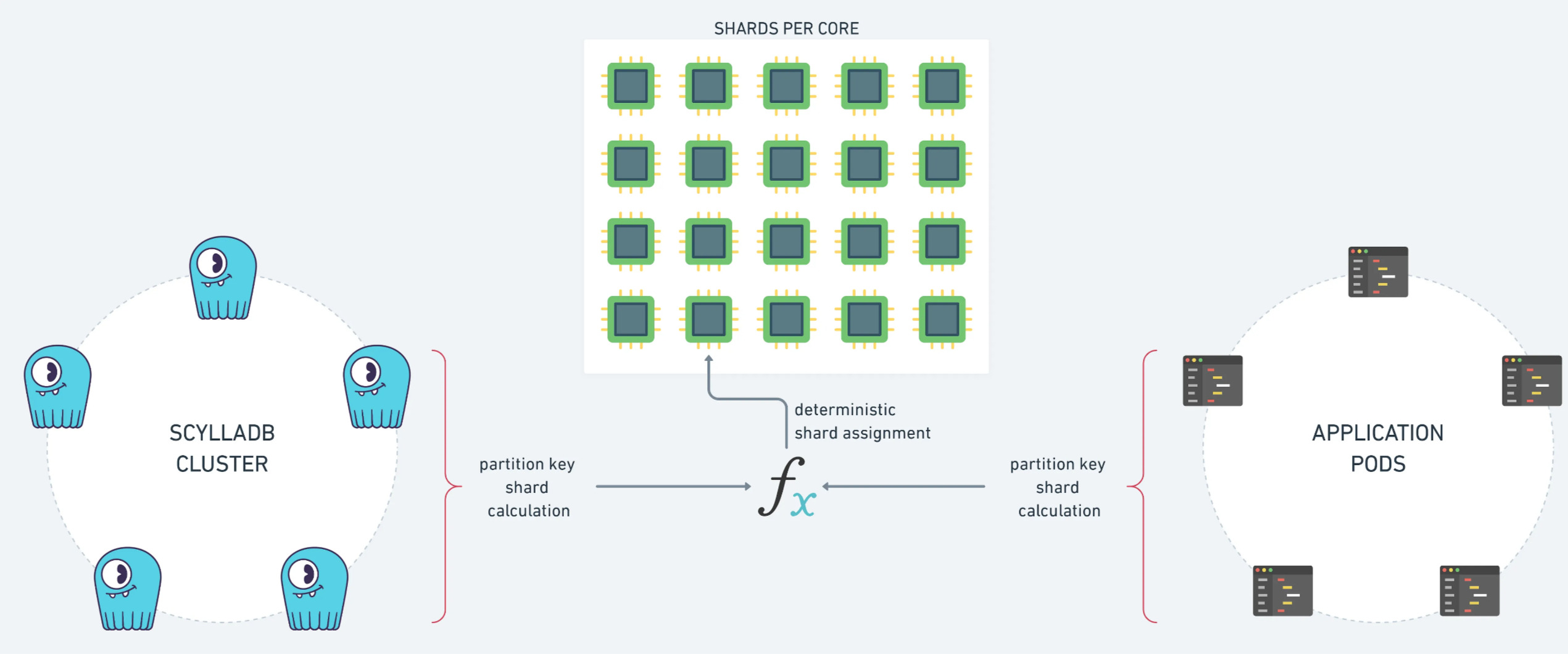
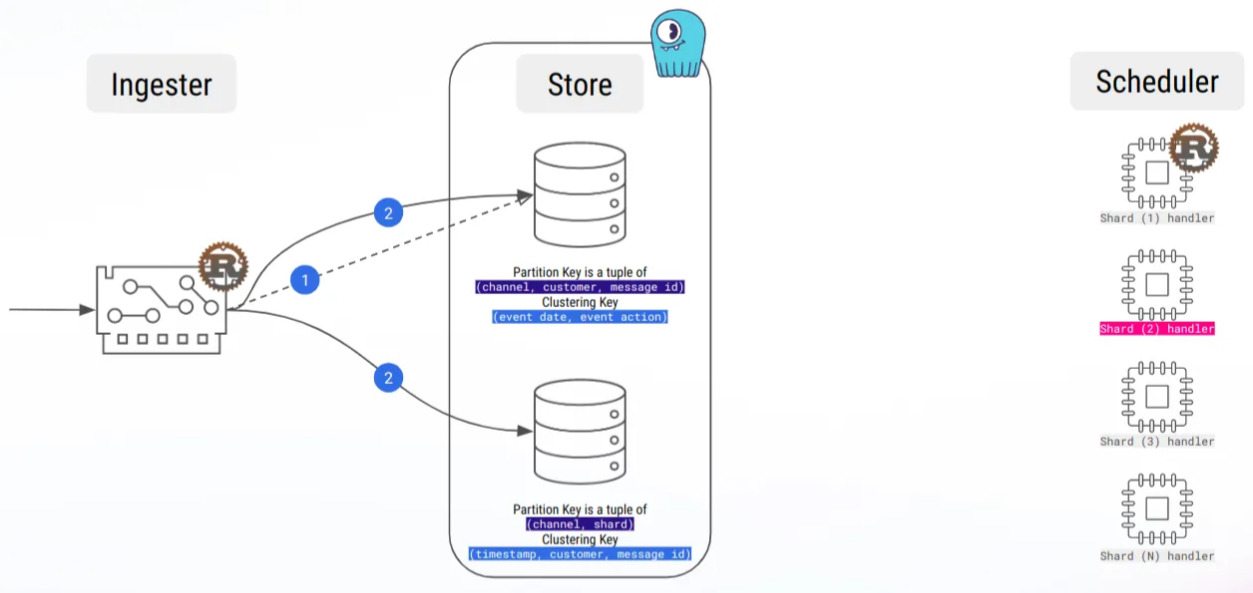
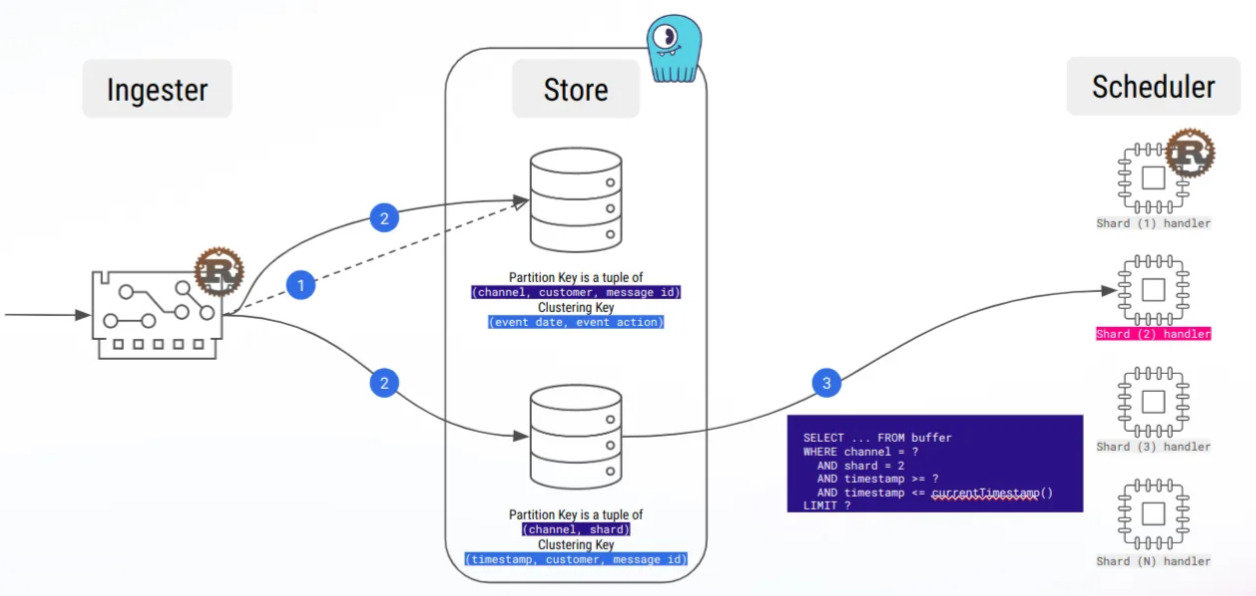
Par exemple, nous avons ajouté le code pour calculer les nœuds de réplique d’une clé primaire, car nous en avions besoin pour calculer le shard d’un message :
Nous espérons que cela vous aidera si vous souhaitez utiliser ce modèle de sharding cool dans votre future application shard-aware !
Nous avons également découvert quelques bugs dans ScyllaDB, nous avons donc travaillé avec le support de ScyllaDB pour les corriger (merci pour votre réactivité).
Ce que nous aimerions faire
Comme dans tous les systèmes, tout n’est pas parfait, et il y a certains points que nous aimerions améliorer.
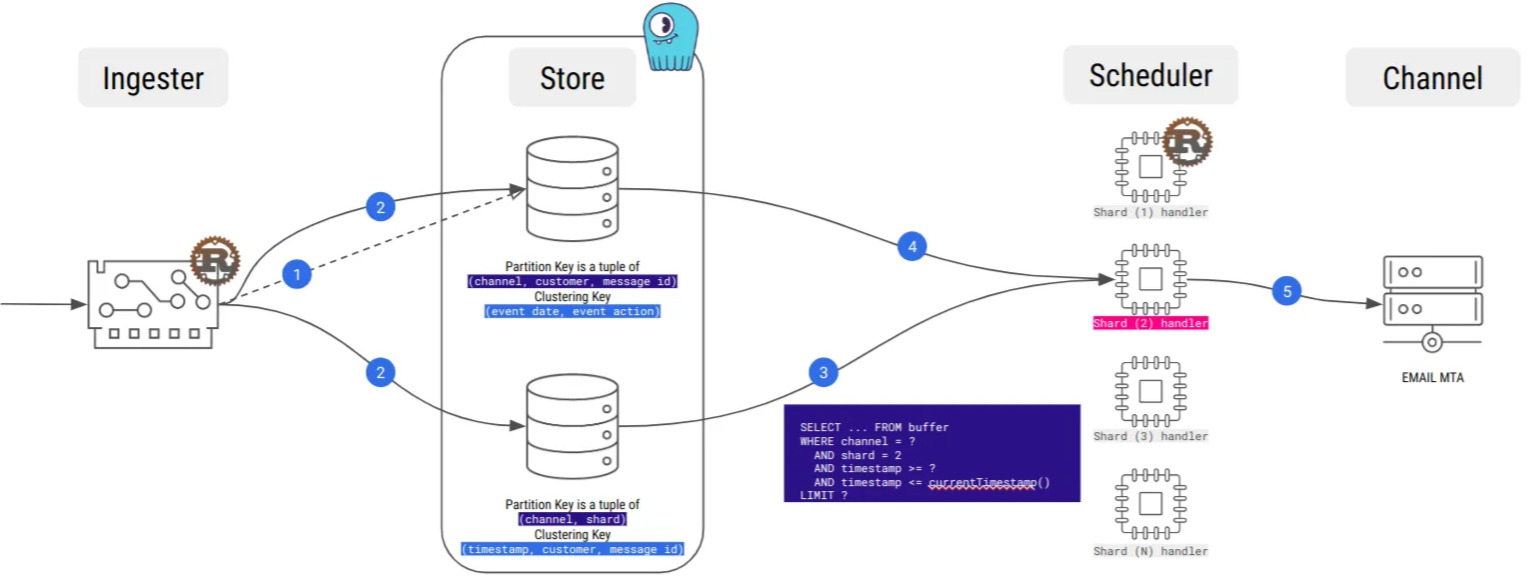
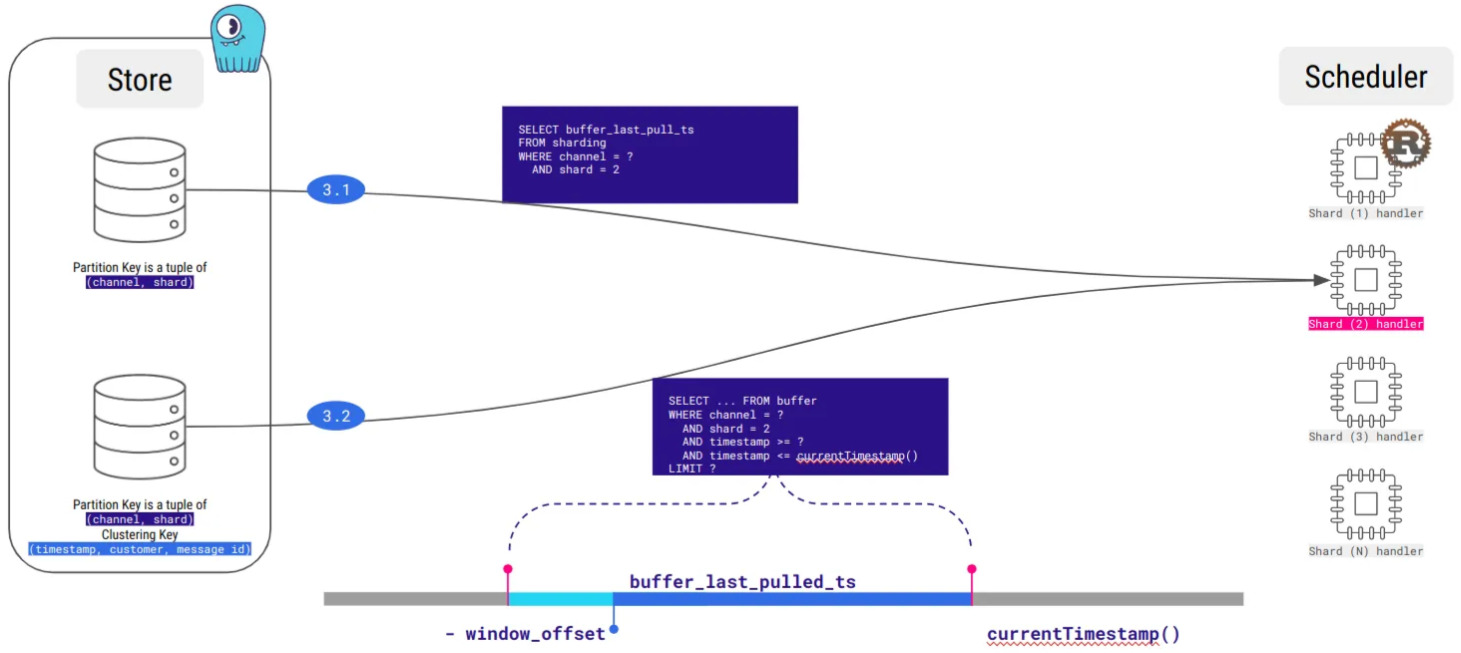
ScyllaDB n’est évidemment pas une plateforme de mise en file d’attente de messages, et le long-polling de Kafka manque à l’appel. Actuellement, notre architecture effectue des recherches régulières dans chaque mémoire tampon, ce qui consomme beaucoup de bande passante inutile, mais nous travaillons à l’optimisation de ce processus.
Nous avons également rencontré quelques problèmes de mémoire, pour lesquels nous avons soupçonné le pilote ScyllaDB Rust. Nous n’avons pas pris beaucoup de temps pour enquêter, mais cela nous a poussé à creuser dans le code du pilote, où nous avons repéré beaucoup d’allocations de mémoire.
Dans le cadre d’un projet parallèle, nous avons commencé à réfléchir à certaines optimisations ; en fait, nous avons fait plus que réfléchir, car nous avons écrit un prototype complet d’un pilote ScyllaDB Rust (presque) sans allocation.
Nous en ferons peut-être le sujet d’un prochain article, avec le pilote Rust surpassant le pilote Go !
Aller plus loin avec les fonctionnalités de ScyllaDB
Nous avons donc misé sur ScyllaDB, et c’est une bonne chose, car il dispose de nombreuses autres fonctionnalités dont nous voulons bénéficier.
Par exemple, la capture des Data Change : en utilisant le connecteur source CDC Kafka, nous pourrions transmettre nos événements de messages au reste de l’infrastructure, sans toucher au code de notre application. L’observabilité en toute simplicité.
Nous attendons avec impatience le cheminement de ScyllaDB vers des tables fortement constantes avec Raft comme alternative à LWT.
Actuellement, nous utilisons LWT à quelques endroits, en particulier pour l’attribution dynamique de la charge de travail, et nous sommes donc impatients de tester cette fonctionnalité !
Écrit par Alexys Jacob, CTO.