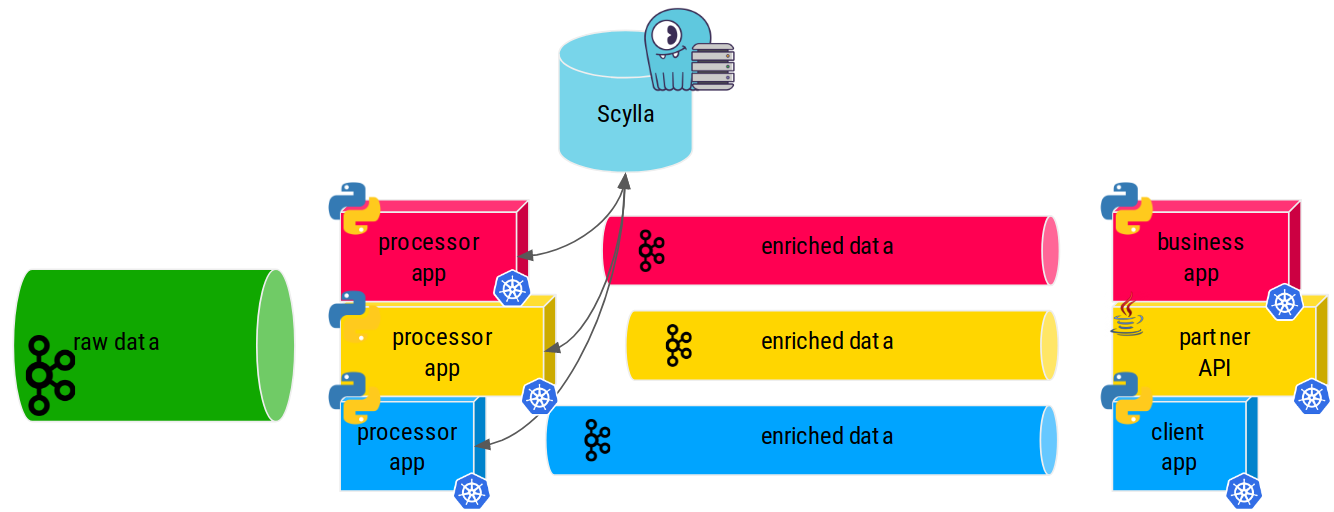
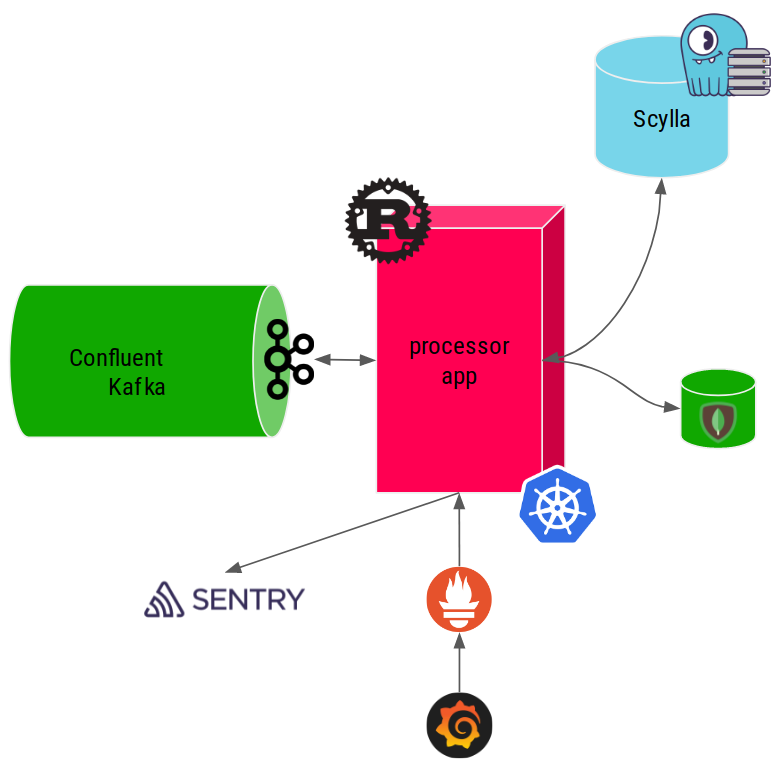
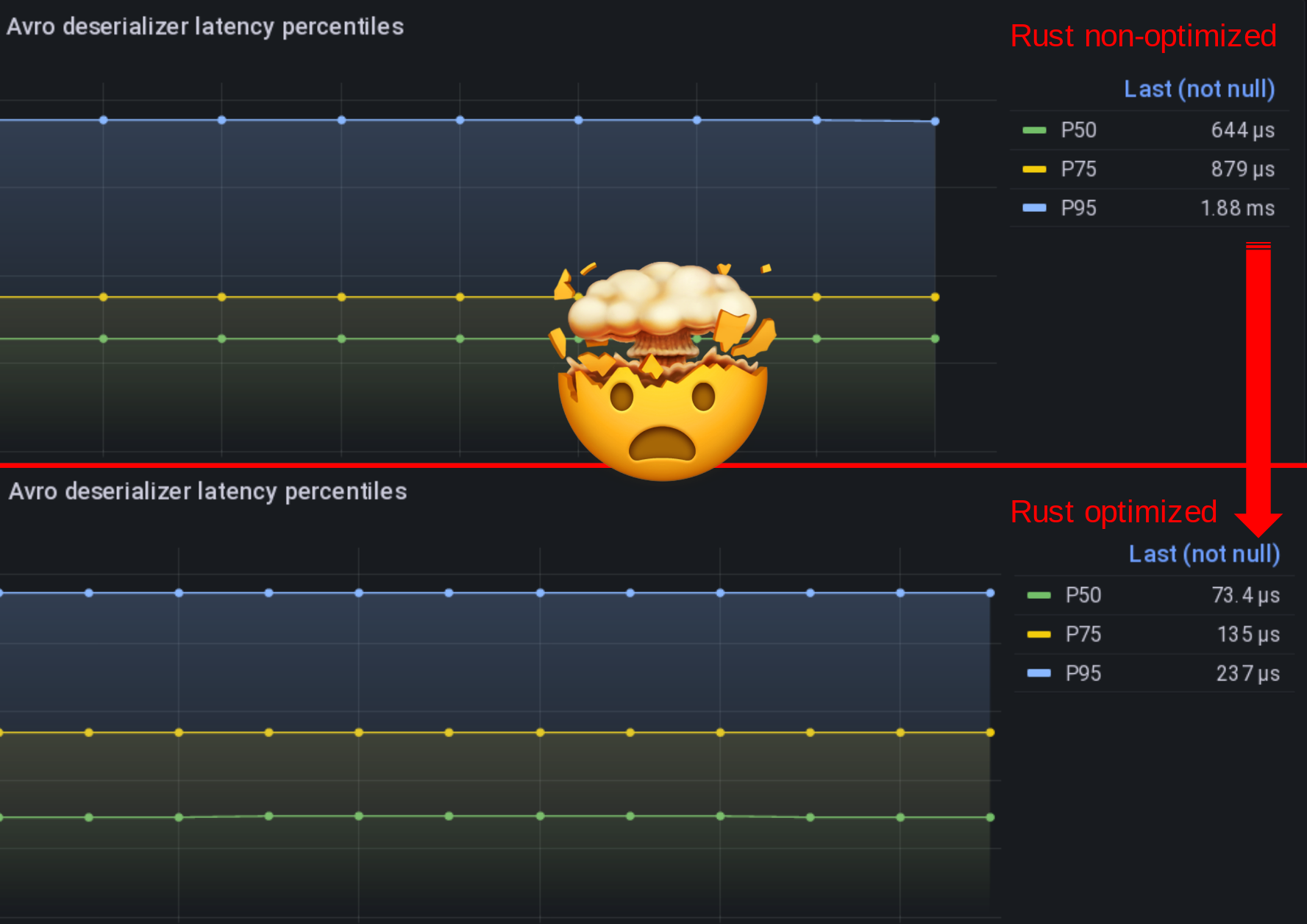
Exporter correctement les métriques pour Prometheus
Passons maintenant à Prometheus qui, même s’il arrive tard dans cette présentation, est en fait l’une des premières choses que j’ai mises en place sur mon application.
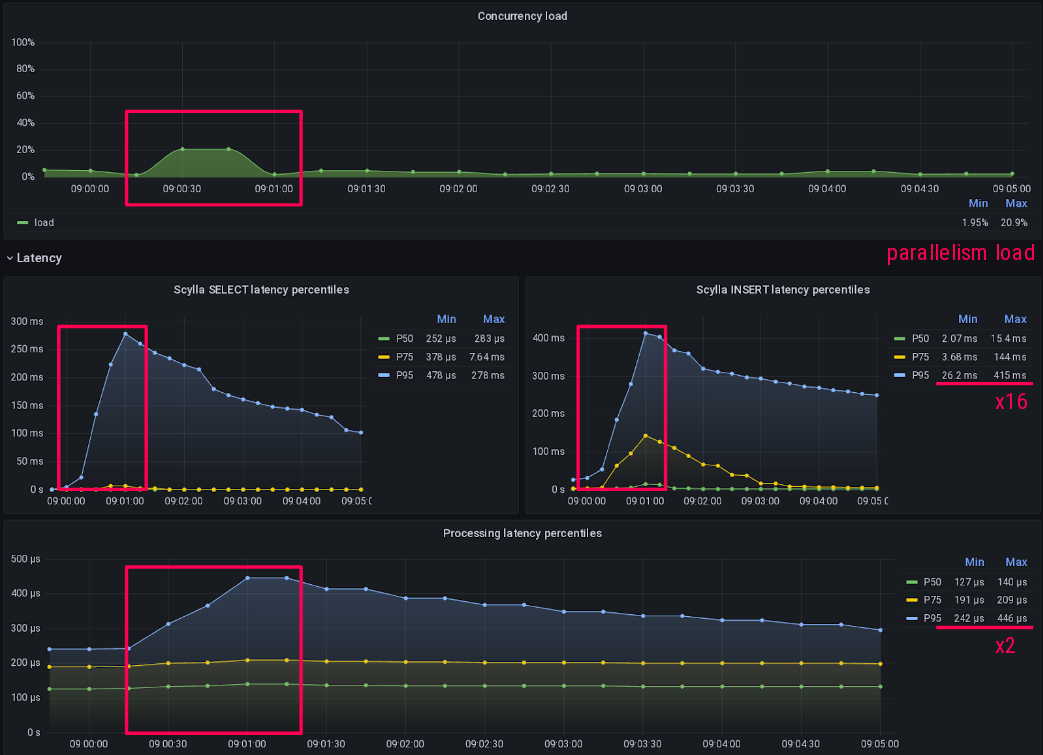
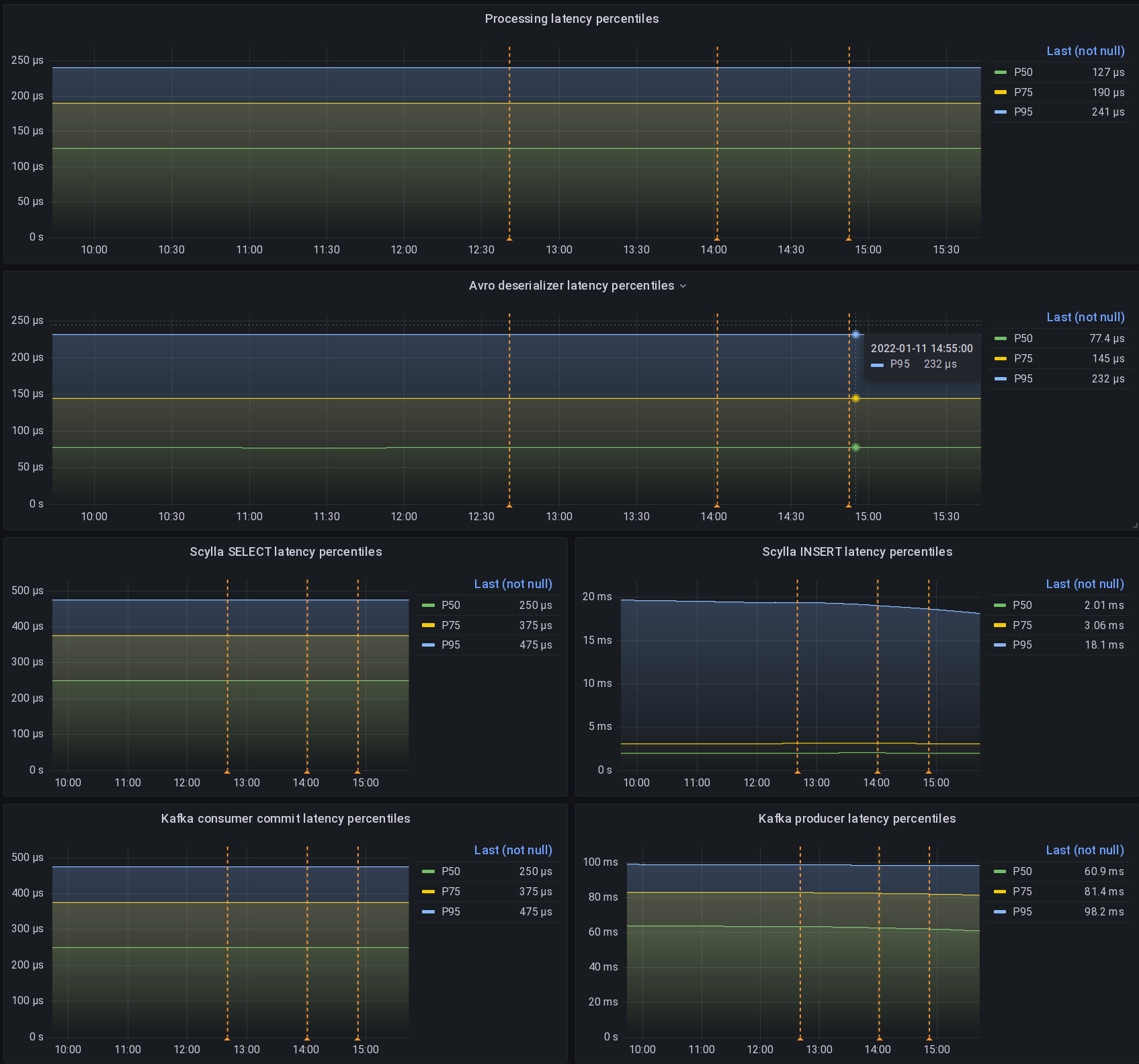
Pour toutes les expériences que j’ai faites, j’ai mesuré leur impact sur la latence et le débit grâce à Prometheus.
Pour qu’un test soit significatif, ces mesures doivent être effectuées correctement, puis représentées graphiquement correctement.
Voici donc un exemple de la façon dont je mesure la latence d’insertion des requêtes de Scylla.
La première et importante difficulté est de configurer correctement votre bucket d’histogramme avec la finesse du graphique attendu :
pub static ref SCYLLA_INSERT_QUERIES_LATENCY_HIST_SEC: Histogram = register_histogram!(
"scylla_insert_queries_latency_seconds",
"Scylla INSERT query latency histogram in seconds",
vec![0.0005, 0.001, 0.0025, 0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0, 5.0, 15.0],
)
.expect("failed to create prometheus metric");
Ici, je m’attends à ce que la latence de scylla varie entre 50µs et 15s, ce qui est le délai d’attente maximal du serveur que j’autorise pour les écritures.
Ensuite, je l’utilise comme ceci : je démarre un timer sur l’histogramme et j’enregistre sa durée en cas de succès; je l’abandonne en cas d’échec afin que mes mesures ne soient pas polluées par d’éventuelles erreurs.
let timer = SCYLLA_INSERT_QUERIES_LATENCY_HIST_SEC.start_timer();
match scylla_session
.execute(scylla_statement, &scylla_parameters)
.await
{
Ok(_) => {
timer.observe_duration();
Ok(())
}
Err(err) => {
drop(timer);
PROCESSING_ERRORS_TOTAL
.with_label_values(&["scylla_insert"])
.inc();
error!("insert_in_scylla: {:?}", err);
Err(anyhow!(err))
}
}