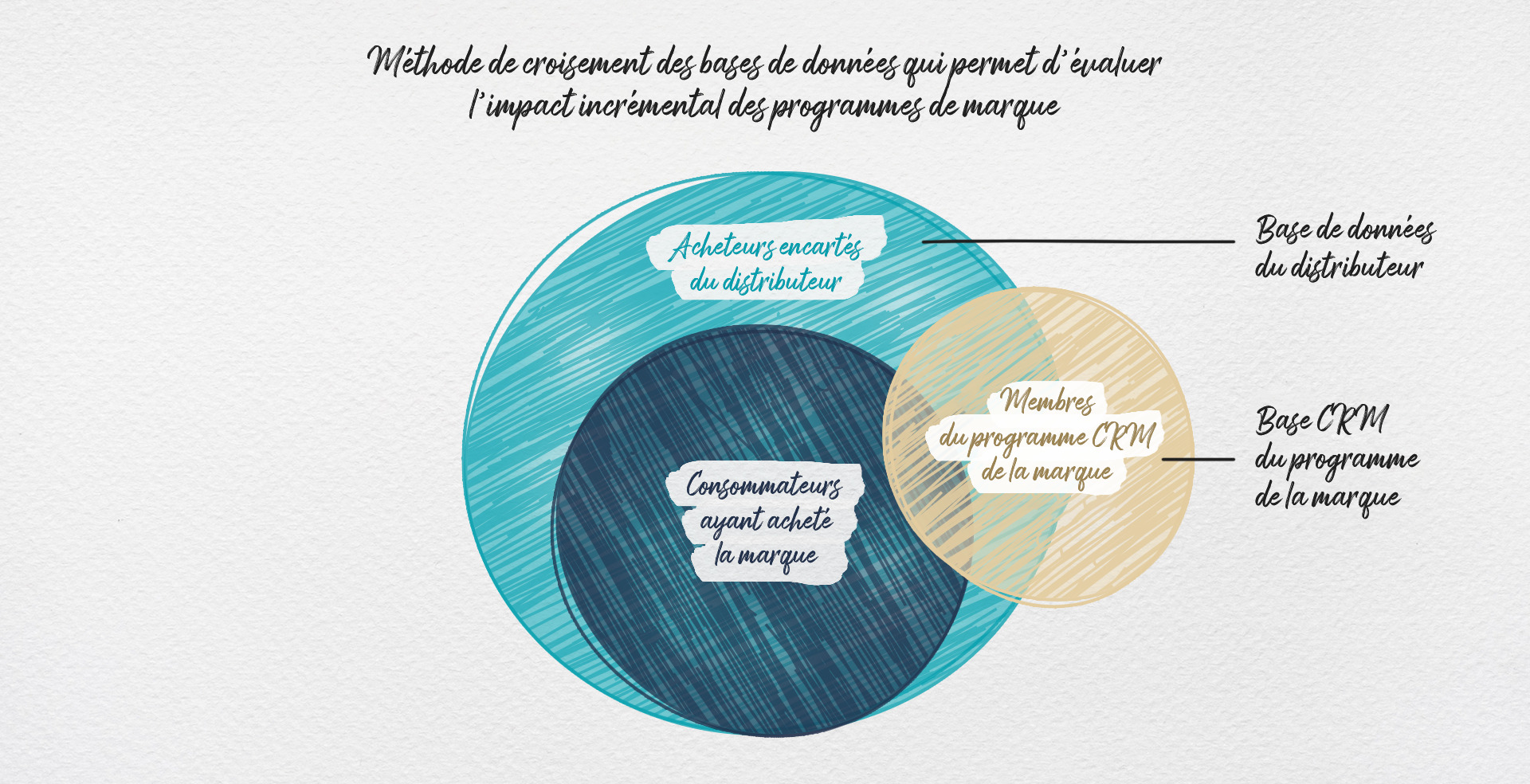
Pour mener à bien cette étude, les équipes de Numberly se sont appuyées sur une Clean Room de distributeur pour rapprocher de façon sécurisée
et pseudonymisée la base d’un distributeur, comprenant des données socio-démographiques et transactionnelles,
avec la base de données CRM du programme de fidélisation d’une marque.
Les individus communs à ces deux bases, c’est-à-dire les individus du programme CRM acheteurs du produit chez le distributeur, constituent ainsi
la population d’étude. Nous avons ensuite sélectionné des individus au profil similaire dans la base du distributeur.
En construisant cette population jumelle non exposée au programme CRM, nous sommes en mesure de comparer
le comportement d’achat de ces deux populations pour estimer
la valeur incrémentale générée par le programme pendant la période d’analyse.
La population jumelle est construite puis redressée à l’aide de critères socio-démographiques et transactionnels
pour être comparable à la population d’étude au début de la période d’analyse.
Cette méthodologie de mesure a posteriori, sans être aussi rigoureuse qu’une démarche expérimentale, permet d’aller plus vite
qu’avec un protocole d’expérience qui aurait été mis en place en amont de l’activation.
Cela permet d’ouvrir des opportunités de mesure plus larges tout en assurant une méthodologie statistiquement robuste
pour évaluer l’impact réel du programme et les leviers de valeur du CRM.